
项目二简介
构建一个高级API封装器:
使用FastAPI,创建一个简单的后端服务。它接收一个任务描述(比如“总结这段文字”或“把这段英文翻译成中文”),然后在内部构建一个高质量的 Prompt,调用 LLM API,最后将 LLM 返回的干净结果作为 API 的响应返回 目的: 将 LLM的 强大能力,封装成可以轻松调用的、可靠的后端服务
解决方案
简单实现
使用 fastAPI 封装一个 API 端点,该端点实现 接收文本 -> 构建 prompt -> 调用 llm -> 返回清洗好的、符合约束的 JSON 内容。
注意,所有内容都在一个 API 里实现,实际上这过于臃肿了。 可以将“构建 prompt”和“llm 调用”这两部分给抽象为独立的模块。例如 prompts module, stateless llm module。之后再有其他新的端点需要实现上面的流程,只需要传入需要的参数即可,不需要写重复的代码。
结构化实现
为保证文章阅读的流畅性,该部分后续给出。
将简单实现的流程的一些内容抽象封装为模块进行调用。
简单方案的实现步骤
1. 初始化 fastAPI 应用
import os
import json
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
from openai import OpenAI
from dotenv import load_dotenv
# 由于国内可能存在的 CDN 流量限制,故手动定义 fastapi 自带的 swagger ui 页面的静态资源加载
# 以下的包的作用是使用国内镜像源加载 fastAPI 自带的 seagger ui 页面
from fastapi.openapi.docs import get_swagger_ui_html
from fastapi.openapi.docs import get_redoc_html
load_dotenv()
app = FastAPI(title="Atri Translator", docs_url=None, redoc_url=None)2. 使用国内镜像CDN加速站加载 swagger ui
# Add swagger-ui mirror
@app.get("/docs", include_in_schema=False)
async def custom_swagger_ui_html():
return get_swagger_ui_html(
openapi_url=app.openapi_url,
title=app.title + " - Swagger UI",
oauth2_redirect_url=app.swagger_ui_oauth2_redirect_url,
swagger_js_url="https://cdn.bootcdn.net/ajax/libs/swagger-ui/5.29.1/swagger-ui-bundle.js",
swagger_css_url="https://cdn.bootcdn.net/ajax/libs/swagger-ui/5.29.1/swagger-ui.css",
)
@app.get("/redoc", include_in_schema=False)
async def redoc_html():
return get_redoc_html(
openapi_url=app.openapi_url,
title=app.title + " - ReDoc",
redoc_js_url="https://unpkg.com/redoc@next/bundles/redoc.standalone.js",
)3. 初始化 llm 客户端
client = OpenAI(
api_key=os.environ.get("ALIYUN_API_KEY"),
base_url=os.environ.get("ALIYUN_BASE_URL"),
)4. 定义 pydantic 模型
以构建一个翻译器为例,定义两个数据模型:一个用于发送消息,一个用于接收返回的消息。
class TranslateRequest(BaseModel):
text: str = Field(..., description="需要翻译的原文", min_length=1)
target_lang: str = Field("English", description="目标语言,默认为英语")
class TranslateResponse(BaseModel):
original_text: str
translated_text: str
detected_language: str = "unknown"5. 处理服务请求
使用 fastAPI 的路由定义和异步请求方式,完成核心的发送-接收逻辑。
# 定义接收的 API 请求的路由
@app.post("/api/translate", response_model=TranslateResponse)
async def translate(request: TranslateRequest):
"""
access text -> build Prompt -> llmcalling -> return JSON well-clear
:param request:
:return: JSON well-clear
"""构建系统 prompt:
system_prompt = f"""
你是一个精通多国语言的资深翻译引擎。
任务:
1. 将用户输入的文本翻译成 {request.target_lang}。
2. 自动检测原文的语言。
3. 必须严格以 JSON 格式输出,包含以下字段:
- translated_text: 翻译后的内容
- source_lang: 原文的语言(如 Chinese, English, French)
示例:
{{
"translated_text": "hello",
"source_lang": "en"
}}
"""构建 API 请求
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": request.text},
],
temperature=0.3,
)接收返回内容并转为字典(因为返回的是 JSON )
content = response.choices[0].message.content
# turn json into dict
data = json.loads(content)将拿到的字典内容返回给客户端
# return to client
return TranslateResponse(
original_text=request.text,
translated_text=data.get("translated_text", "Fail to translate"),
detected_language=data.get("source_lang", "unknown"),
)定义根目录路由(用于测试 UI 界面正常打开)
@app.get("/")
async def root():
return {"message": "AI server is running! please open thr link /docs to see docs."}运行指令
uvicorn main:app --reload或者
fastapi dev main.py --port 8000然后打开 http://127.0.0.0:8000。
如果出现长时间打不开 UI 页面的情况,有可能是端口被占用。使用
--port指令切换端口。
架构重构
就像前文说的,处理 接收请求 -> 构建 prompt -> llm 调用 -> 解析响应 -> 返回需要的数据结构 的所有代码全部堆积在一个 API 端点里。这样代码容易臃肿,且有几个部分是可以代码复用的。例如 prompt 构建、llm 调用和解析响应。
因此可以做出以下重构:
- 借用 MVC 设计思路,将逻辑划分为:服务层、配置层。
- 配置层:进行 fastapi 的配置,例如标题、描述、启动端口、启动入口等
- 服务层:业务处理、prompt工厂、Pydantic模型定义、llm 调用
project_two
┣ config
┃ ┣ config.py
┣ services
┃ ┣ llmcalling.py
┃ ┣ prompt_factory.py
┃ ┣ schema.py
┃ ┣ server.py
┣ main.py这样的结构增加了可扩展性和稳定性。
实际上配置文件在 /project_two 下创建 .env 作为子配置文件(项目根目录有根
.env), 从环境里读取所有配置才是生产环境的标准做法
这样对于业务处理代码部分(API 端点)不必再写多余的代码以及考虑 llm 调用、prompt 构建、结构解析等部分的代码,直接调用相关的方法即可。
对于 server.py,其原本的业务处理逻辑不变,但是代码已被精简为:
@app.post("/api/translate", response_model=TranslateResponse)
async def translate(request: TranslateRequest):
"""
access text -> build Prompt -> llmcalling -> return JSON well-clear
:param request:
:return: JSON well-clear
"""
system_prompt = PromptFactory.get_translate_prompt(request.target_lang)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": request.text},
]
content = llmcalling("qwen3-max", messages, 0.3)
# turn json into dict
data = json.loads(content)
# return to client
return TranslateResponse(
original_text=request.text,
translated_text=data.get("translated_text", "Fail to translate"),
detected_language=data.get("source_lang", "unknown"),
)只需构建好传入模型的 message 部分,再将结果返回即可。代码高度精简和可读。
而需要构建新的(例如角色扮演等和 llm 互动)API 端点时,也是一样的处理逻辑,只需要在 prompt 工厂里新增系统 prompt即可。
重构后的代码可在此 commit 查看:https://github.com/JuyaoHuang/AI-agent/pull/9/commits/9544f2f8c77739cce1cef9a379c2463cc5b7555f
该 commit 还没有将 llmcalling 抽象出来。
实践扩展一
Issue 链接:https://github.com/JuyaoHuang/AI-agent/issues/8
项目 2 的基本需求已完成。项目结构已成功重构为标准的 MVC 架构。基于此坚实的基础,我计划进一步扩展项目的功能。
目标
此问题跟踪以下扩展的实现:
-
实现 /api/summary 端点:创建一个用于文本摘要的新 API 路由,利用 PromptFactory 管理摘要相关的提示,为此任务建立一个新的 LLM 调用流程。
-
开发客户端模拟脚本:编写一个 Python 脚本来模拟真实用户的请求,从客户端的角度验证 API 的行为和性能。
-
全栈集成(Streamlit):将现有的 Streamlit 前端(来自项目 1)与新构建的 FastAPI 后端集成,实现无缝的前后端通信。
实施方案及技术细节
- 重构 LLM 服务:将核心 LLM 调用逻辑抽象为可重用的服务方法/类,以减少代码重复并提高可维护性。
- 客户端逻辑:使用 Python requests 库处理 API 调用并解析返回的 JSON 数据结构。
- 前端渲染:在 Streamlit UI 上渲染解析后的 API 响应。
- 目标:实现流式输出(如适用)以提升用户体验。
实现代码
new prompt 构建
@staticmethod
def get_summary_prompt(word_limit: int=100) -> str:
"""
Generate summary task system prompt
:param word_limit:
:return:
"""
return f"""
# Role
你是一个专业的文章摘要助手,擅长将长文本内容做总结,总结的内容精准、周到,
最大化保留了长文本的信息。
# Task
- 请将文章总结在 {word_limit} 字以内
- 将文章的内容提取出数个关键词作为 tags
# Format
必须返回 JSON 格式:{{ "summary": "...", "tags": [] }}
# Example
{{
"summary": "这是一篇科技杂志文章...",
"tags":['AI', '英伟达', '科技']
}}
"""模型构建
class SummaryRequest(BaseModel):
text: str = Field(..., description="需要总结的长文本", min_length=1)
word_limit : int = Field(100, description="限制的字数,默认 100 字")
class SummaryResponse(BaseModel):
summary: str
tags: list[str] = Field(...)API 端点构建
# 辅助函数:清洗模型可能返回的 ```json 代码块标注
def clean_json_string(text:str) -> str:
"""清理模型返回的可能存在的 markdown 标记:```json """
text = re.sub(r"```json\s*", "", text)
text = re.sub(r"```", "", text)
return text.strip()
@app.post("/api/summary", response_model=SummaryResponse)
async def summary(request: SummaryRequest):
"""处理总结长文本请求的端点"""
system_prompt = PromptFactory.get_summary_prompt(250)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": request.text},
]
content = LLMCalling.llmcalling("qwen3-max", messages, 0.5)
# 清洗潜在的 json md标注
content = clean_json_string(content)
data = json.loads(content)
return SummaryResponse(
summary=data.get("summary", "Fail to summary"),
tags=data.get("tags",[])
)创建测试脚本
import requests
def translate_test(text: str, target_lang: str):
url = "http://127.0.0.1:8028/api/translate"
payload = {
"text": text,
"target_lang": target_lang
}
print("正在调用翻译 API...")
response = requests.post(url, json=payload)
if response.status_code == 200:
data = response.json()
print(f"翻译结果: {data['translated_text']}")
print(f"识别语言: {data['detected_language']}")
else:
print("调用失败:", response.text)
def summary_test(text: str, word_limit: int):
url = "http://127.0.0.1:8028/api/summary"
pay_load = {
"text": text,
"word_limit": word_limit
}
print("正在调用总结摘要 API...")
response = requests.post(url, json=pay_load)
if response.status_code == 200:
data = response.json()
print(f"摘要:{data['summary']}")
print(f"标签:{data['tags']}")
else:
print("调用失败:", response.text)
if __name__ == '__main__':
print("测试:翻译或者总结\n")
op = input("输入要调用的API: ")
if op == '翻译':
text = input("输入要翻译的内容:")
lang = input("输入要翻译的语言:")
translate_test(text, lang)
elif op == "总结":
text = input("输入要总结的长文本:")
word_limit = int(input("输入限制的字数:"))
summary_test(text, word_limit)前端渲染
首先构建 API 客户端,封装请求
import requests
BASE_URL = "http://127.0.0.1:8028"
def api_translate(text: str, target_lang: str):
"""调用后端翻译接口"""
url = f"{BASE_URL}/api/translate"
payload = {
"text": text,
"target_lang": target_lang
}
print("正在调用翻译 API...")
try:
response = requests.post(url, json=payload)
if response.status_code == 200:
return response.json()
else:
return {"error": f"API 调用失败: {response.text}"}
except requests.exceptions.ConnectionError:
return {"error": "无法连接到后端服务,请检查 FastAPI 是否已启动 (Port 8028)"}
def api_summary(text: str, word_limit: int):
"""调用后端摘要接口"""
url = f"{BASE_URL}/api/summary"
payload = {
"text": text,
"word_limit": word_limit
}
print("正在调用总结摘要 API...")
try:
response = requests.post(url, json=payload)
if response.status_code == 200:
return response.json()
else:
return {"error": f"API 调用失败: {response.text}"}
except requests.exceptions.ConnectionError:
return {"error": "无法连接到后端服务,请检查 FastAPI 是否已启动 (Port 8028)"}构建前端
import streamlit as st
import sys
import os
# 获取当前脚本所在的绝对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 将这个路径加入到 Python 的搜索路径 (sys.path) 中
if current_dir not in sys.path:
sys.path.append(current_dir)
# 别理会 IDE 的报错
from utils.client_script import api_summary, api_translate
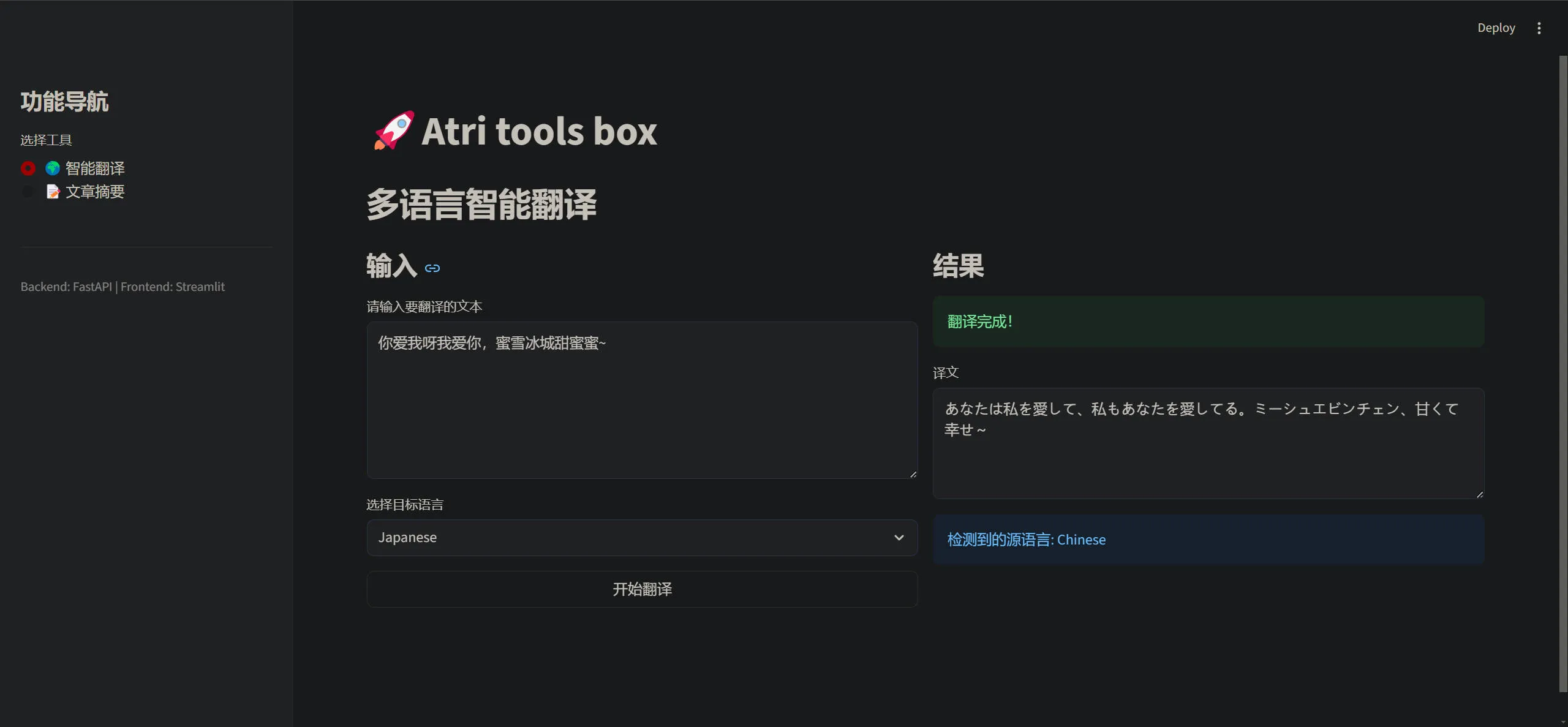
st.set_page_config(page_title="Atri tools box", page_icon="🧰", layout="wide")
st.title("🚀Atri tools box")
st.sidebar.title("功能导航")
page = st.sidebar.radio("选择工具", ["🌍 智能翻译", "📝 文章摘要"])
if page == "🌍 智能翻译":
st.header("多语言智能翻译")
# 左右布局:左边输入,右边显示结果
col1, col2 = st.columns(2)
with col1:
st.subheader("输入")
input_text = st.text_area("请输入要翻译的文本", height=200, placeholder="在此输入...")
target_lang = st.selectbox(
"选择目标语言",
["English", "Chinese", "Japanese", "French", "German", "Spanish"]
)
submit_btn = st.button("开始翻译", use_container_width=True)
with col2:
st.subheader("结果")
result_container = st.empty()
if submit_btn and input_text:
with st.spinner("AI 正在思考中..."):
result = api_translate(input_text, target_lang)
if "error" in result:
st.error(result["error"])
else:
st.success("翻译完成!")
st.text_area("译文", value=result['translated_text'], height=150)
st.info(f"检测到的源语言: {result['detected_language']}")
elif page == "📝 文章摘要":
st.header("长文本智能摘要")
input_text = st.text_area("请输入长文章", height=250)
# 滑块控制字数
word_limit = st.slider("摘要字数限制", min_value=50, max_value=500, value=100, step=10)
if st.button("生成摘要"):
if not input_text:
st.warning("请先输入文本!")
else:
with st.spinner("AI 正在阅读文章并总结..."):
result = api_summary(input_text, word_limit)
if "error" in result:
st.error(result["error"])
else:
st.divider()
st.subheader("📄 摘要内容")
st.write(result['summary'])
st.subheader("🏷️ 关键标签")
try:
st.pills("Tags", result['tags'])
except AttributeError:
st.write(" | ".join([f"`{tag}`" for tag in result['tags']]))
# streamlit run llmcalling/project_two/fronted/fronted.py运行效果
后端 fastAPI 执行 python main.py,前端 Streamlit 执行 streamlit run llmcalling/project_two/fronted/fronted.py
Summary Issue #8:
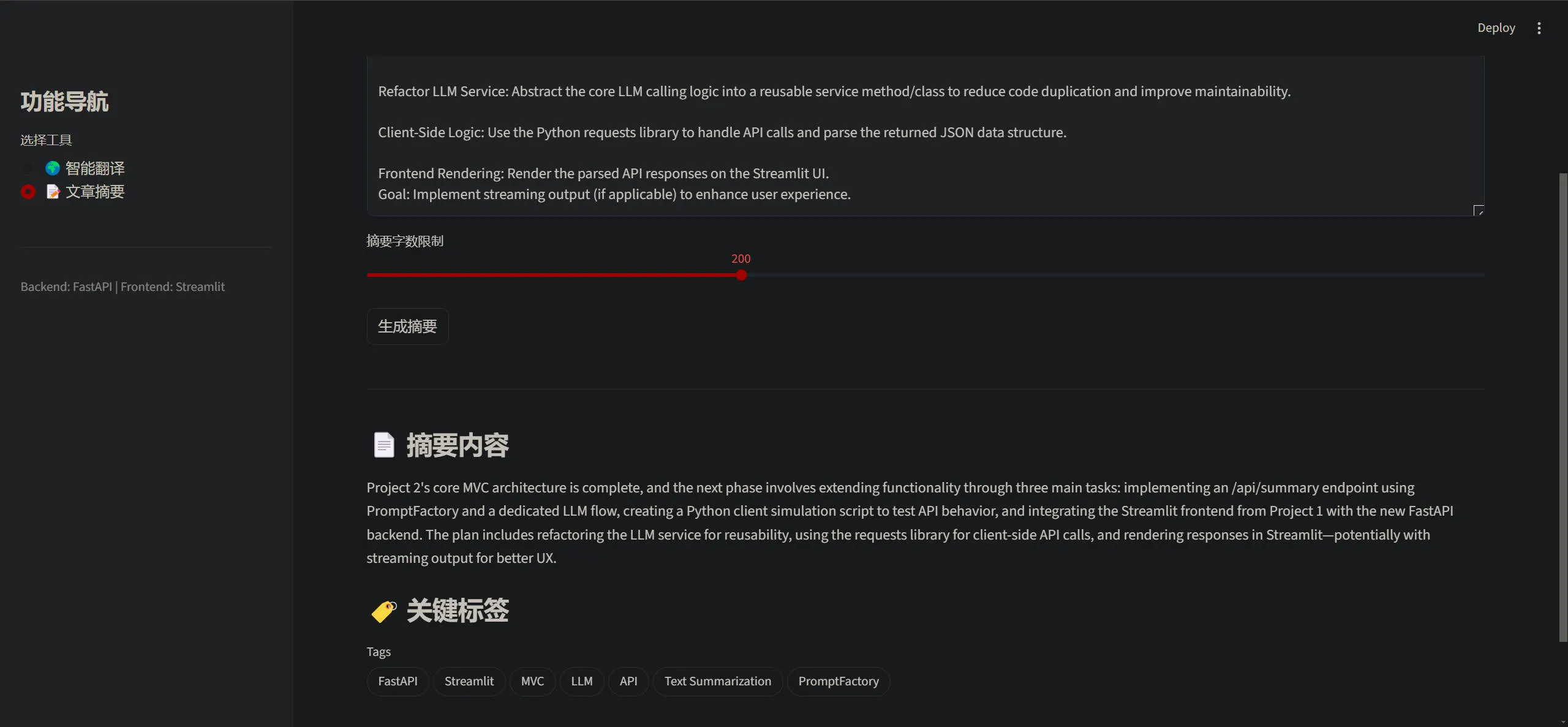
Project 2's core MVC architecture is complete, and the next phase involves extending functionality through three main tasks: implementing an /api/summary endpoint using PromptFactory and a dedicated LLM flow, creating a Python client simulation script to test API behavior, and integrating the Streamlit frontend from Project 1 with the new FastAPI backend. The plan includes refactoring the LLM service for reusability, using the requests library for client-side API calls, and rendering responses in Streamlit—potentially with streaming output for better UX.LLM 重构
将大语言模型调用的部分抽象为一个新的方法,提供接口,接收返回的文本块。
注意:一般的 web 请求流程都是:前端发送请求 -> 后端发送 llm 请求 -> 接收完整内容/流式块 -> 后端将响应内容发给前端渲染。因此后续前后端集成时需要使用流式输出,增强用户的体验。这样就无法使用返回完整的响应后再将其传给前端了,而是将调用 llm 时返回的每一个块都将其传给前端
由此,LLM 调用时应提供三个方法,分别对应于:
- 单次完整输出:后端构建请求完整的响应文本 content
- 流式输出:使用流式输出的方式返回响应文本,不使用思考模式,因此不需要进行结构化流式传输,只需要传输模型输出的文本内容即可。
- 思考模式:由于使用流式输出时不能让大模型输出的内容为 json 格式,因此需要在接收大模型的输出后手动构建结构化的流式输出。
注意:启用流式输出时,模型不应该使用 json 格式输出,而时纯文本样式。
后两种实现比较复杂,本实践先使用第一种方式,后续再做单独的扩展和介绍。
DeepSeek 的 APP 应用里使用的就是第三种,思考模式。
实现思路
1. 单次完整输出
这个没什么好说的,就是直接 return response.choices[0].message.content,即返回模型的输出即可。
2. 流式输出
要实现流式输出,就要改变两个核心逻辑:
- LLM 调用层:不能一次性
return结果,而是使用 Python 的生成器yield,像挤牙膏一样把数据一点点挤出来。 - fastAPI 服务层:不能返回普通的 JSON 对象,而是要返回 StreamingResponse,它会建立一个长连接,把 LLM 挤出来的数据实时推给前端
注意:
- 流式输出和要求模型输出格式为 JSON这两点是违背的。因为启用流式输出时,很难将 JSON 格式的数据提取响应文本(因为是块状数据,不是一条完整的响应文本)
- 流式输出下,流式接口一般使用 SSE (Server-Sent Events) 协议定义模型或者不需要使用 Pydantic 模型传输响应
实现代码:
-
在调用大模型时,构建新的方法,而且将其变为生成器。
def llmcalling_stream_block(model: str, messages: list, temperature: int) -> Generator[str, None, None]: yield content -
修改 fastAPI 服务层,使用流式响应 StreamingResponse 传输文本
return StreamingResponse(stream_generator, media_type="text/event-stream") -
可使用脚本模拟前端的请求和显示情况
3. 思考模式
思考模式比较复杂,因为模型输出是纯 markdown 格式,需要自己手动构建 JSON 格式进行传输。换言之,需要前后端约定数据格式,实现结构化流式传输。
我们需要指定一个简单的协议约定,发送 JSON 字符串,每一行带上类型标签,告诉前端这一块数据是思考内容还是回复内容。
例如:
{"type": "thinking", "content": "我正在分析..."}
{"type": "thinking", "content": "检索数据库..."}
{"type": "answer", "content": "你好"}
{"type": "answer", "content": ","}
{"type": "answer", "content": "世界"}关键代码实现:
-
LLM 调用模块:
新建 llmcalling_thinking 方法,让它返回带有类型标签的 JSON 字符串,而不是纯文本。
@staticmethod def llmcalling_thinking(model: str, messages: list, temperature: int) -> str: for chunk in response: # 1. 处理 token 统计信息 if not chunk.choices: if chunk.usage: yield json.dumps({ "type": "usage", "content": chunk.usage.model_dump()# 转成字典 }, ensure_ascii=False) + "\n" delta = chunk.choices[0].delta # 2. 处理思考过程 reasoning = getattr(delta, "reasoning_content", None) if reasoning: data = { "type": "thinking", "content": reasoning } yield json.dumps(data) + "\n" # 3. 处理 Content elif delta.content: data = { "type": "answer", "content": delta.content } yield json.dumps(data, ensure_ascii=False) + "\n" -
fastAPI 服务层
使用 NDJSON 协议进行 json 块的数据传输
# 返回流式响应 # media_type="application/x-ndjson" 表示 "Newline Delimited JSON" # 一种标准的按行分割 JSON 的格式 return StreamingResponse(stream_generator, media_type="application/x-ndjson")如果你用普通的 application/json,浏览器会期待收到一个合法的 JSON 对象(比如一个巨大的 {…} 或 […])。在数据流传输完成之前,浏览器通常认为 JSON 还没接收完,可能不会触发渲染,或者报错。
而 NDJSON (Newline Delimited JSON) 是一种标准协议,它的规则是:
- 每一行都是一个独立的、合法的 JSON 对象
- 行与行之间用 \n 分隔
前端收到这种 Header 后的反应:
前端(比如用 fetch API)看到这个 content-type,或者在处理流时,就知道应该读一行,解析一行,渲染一行,而不是傻傻地等整个请求结束
总结
- 构建:用 json.dumps(…) + “\n”
- 传输: 用 StreamingResponse
- 声明: 用 media_type=“application/x-ndjson”
这套组合拳是目前处理 LLM 复杂流式输出(如 DeepSeek/OpenAI 的 function calling)的行业标准做法。
实践扩展二
要求
为了提升用户体验,我们需要从当前的“等待完全生成后一次性返回”模式,升级为“流式输出”模式。特别针对支持深度思考的模型(如 qwen3-vl-32b-thinking / DeepSeek-R1),后端需要能够区分并实时返回 思考过程 和 **正式回复 **,以便前端能够将它们分开渲染(例如:思考过程显示在折叠面板中)
🎯 实现目标
- LLM 调用层新增调用方法
- 将
llmcalling方法扩展支持stream=True。 - 适配
extra_body参数以开启思考模式(enable_thinking: True) - 实现生成器 (Generator),能够区分
reasoning_content和content - 处理
usage信息(Token 消耗统计)
- 将
- 定义流式传输协议
- 采用 NDJSON (Newline Delimited JSON) 格式传输数据
- 定义消息类型:
thinking(思考中),answer(回答中),usage(统计)
- 更新 FastAPI 服务层
- 新增接口
/api/translate/stream-thinking - 使用
StreamingResponse返回流式数据 - 确保
media_type设置为application/x-ndjson
- 新增接口
1. 单次请求完整的响应
实现最简单的、最稳定的,在 API 请求里最常使用的方式:一次请求直接返回完整的文本回复(JSON格式返回)。
prompt 构建
f"""
你是一个精通多国语言的资深翻译引擎。
任务:
1. 将用户输入的文本翻译成 {target_lang}。
2. 自动检测原文的语言。
3. 必须严格以 JSON 格式输出,包含以下字段:
- translated_text: 翻译后的内容
- source_lang: 原文的语言(如 Chinese, English, French)
示例:
{{
"translated_text": "hello",
"source_lang": "en"
}}
"""LLM 调用构建
class LLMCalling:
@staticmethod
def llmcalling(model: str, messages: list, temperature: float) -> str:
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
)
return response.choices[0].message.content服务层 API 请求方法
@app.post("/api/translate", response_model=TranslateResponse)
async def translate(request: TranslateRequest):
try:
system_prompt = PromptFactory.get_translate_prompt(request.target_lang)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": request.text},
]
content = LLMCalling.llmcalling("qwen3-max", messages, 0.3)
data = json.loads(content)
return TranslateResponse(
original_text=request.text,
translated_text=data.get("translated_text", "Fail to translate"),
detected_language=data.get("source_lang", "unknown"),
)
except Exception as e:
print(f"Error:{e}\n")
raise HTTPException(status_code=502, detail=str(e))测试脚本
import requests
url = "http://127.0.0.1:8026/api/translate"
payload = {
"text": "Life is like a box of chocolates.",
"target_lang": "Chinese"
}
print("正在呼叫后端...")
response = requests.post(url, json=payload)
if response.status_code == 200:
data = response.json()
print(f"翻译结果: {data['translated_text']}")
print(f"识别语言: {data['detected_language']}")
else:
print("调用失败:", response.text)输出:
正在呼叫后端...
翻译结果: 生活就像一盒巧克力。
识别语言: English