
《神经网络与深度学习》课程实验作业
实验内容:计算机视觉基础
注意事项:
① 本次实验包含一道题,共计20分;
② 部分问题根据学号不同需进行不同的配置,若完成内容与实验要求不对应,则该项记为0分;
③ 所有实验结果需以实验报告的形式进行提交,文件命名格式:实验二_姓名_学号.pdf;
④ 实验报告中可插入代码片段,完整代码无需放在实验报告中,以压缩包的形式添加即可,压缩包命名格式:实验二代码_姓名_学号.zip;
⑤ 作业提交截止时间:2025年12月31日24:00前。
卷积神经网络与经典卷积神经网络模型(20分)
food-11数据集是深度学习中常用的一类数据集,其中包含11类食物的图片,分别是:Bread, Dairy product, Dessert, Egg, Fried food, Meat, Noodles/Pasta, Rice, Seafood, Soup, and Vegetable/Fruit. 数据集中包含9866张训练集,3430张验证集,3347张测试集。其中training和validation目录下的照片命名格式为“[类别]_[编号].jpg”
请基于该数据集,完成以下实验内容:
(1) 请根据已有数据集,对training和validation进行处理,构造训练数据集;(3分)
(2) 为了保证数据的训练性能,请利用torchvision.transforms设计属于你的train_transform,train_transform模版已事先给出。你所设计的train_transform需要指定你所选择的特征图大小,并至少由五种transform组成;(3分)
(3) 对你所设计的train_transform进行可视化,将变换后的结果进行可视化展示;(2分)
(4) 搭建好个人设计的训练模型,并利用tensorboard对过程进行可视化展示;(2分)
(5) 在验证集上显示你的准确性和混淆矩阵;(2分)
(6) 将个人设计模型对测试集预测结果输出到ans_ours.csv中;(3分)
(7) 请自行查询资料,搭建VGG系列模型,并打印模型参数;(2分)
(8) 使用VGG系列模型对测试集进行预测,并将结果输出到ans_vgg.csv中;(3分)
Food11数据集链接:https://www.kaggle.com/datasets/vermaavi/food11
提示:
①该数据集的标签需要自行根据文件名进行提取;
②数据集中图片大小并不统一;
③VGG系列模型主要包含VGG16和VGG19,你可以从中任选一个进行实现
题目分析
第一阶段:数据工程
任务 (1): 构造训练数据集 (3分)
- 核心要求:编写代码读取
training和validation文件夹下的图片 - 关键动作:
- 需要自定义一个 Dataset 类
FoodDataset(继承torch.utils.data.Dataset) - 文件名解析:图片名格式为
[类别]_[编号].jpg(例如Bread_001.jpg)。需要写代码解析字符串,把Bread映射成数字标签(例如0) - 注意:要确保训练集和验证集的类别映射关系是一致的(比如 Bread 在训练集是 0,在验证集也必须是 0)
- 需要自定义一个 Dataset 类
任务 (2): 设计 Train Transform (3分)
- 核心要求:利用
torchvision.transforms对图片进行预处理和增强 - 硬性指标:
- 指定特征图大小:必须包含
Resize(例如Resize((224, 224))),因为题目提示图片大小并不统一 - 至少五种 Transform:少于5种扣分
- 指定特征图大小:必须包含
- 建议组合:
Resize((224, 224))(必选)RandomHorizontalFlip()(水平翻转)RandomRotation()(随机旋转)ColorJitter()(颜色抖动)RandomAffine(): 随机仿射变换 (平移、缩放)ToTensor()(转张量,必选)Normalize()(归一化,必选)
任务 (3): Transform 可视化 (2分)
- 核心要求:展示图片在经过你设计的 Transform 处理后变成了什么样
- 操作:取一张原始图片,应用你的 transform,然后用
matplotlib.pyplot.imshow画出来 - 坑点:如果 transform 里包含了
Normalize,图片颜色会变得很奇怪(因为数值被标准化了)。在可视化时,建议先展示不带 Normalize 的增强效果,或者编写一个反归一化函数再显示
第二阶段:自定义模型
任务 (4): 搭建个人模型 & TensorBoard 可视化 (2分)
- 核心要求:
- 自定义一个简单的 CNN 类(比如 3-4 层卷积层)
- 使用
SummaryWriter记录训练过程中的 Loss 和 Accuracy
- 交付物:报告中必须要有 TensorBoard 的截图(Loss曲线下降,Accuracy曲线上升)
任务 (5): 验证集评估 & 混淆矩阵 (2分)
- 核心要求:模型训练完后,在验证集(Validation Set)上跑一遍
- 交付物:
- 准确率数值:例如 “Validation Accuracy: 65.4%”
- 混淆矩阵图:这是一个 11x11 的热力图。它可以告诉你模型是不是把“Bread(面包)”错误地分类成了“Dessert(甜点)”。需要使用
sklearn.metrics.confusion_matrix和seaborn.heatmap
任务 (6): 测试集预测输出 (3分)
- 核心要求:用训练好的模型对无标签的
testing文件夹里的图片进行预测 - 交付物:生成
ans_ours.csv文件 - 格式:CSV 需要两列:
Id(文件名) 和Category(预测的类别数字)
第三阶段:经典模型 (VGG)
任务 (7): 搭建 VGG 模型 & 打印参数 (2分)
-
核心要求:实现 VGG16 或 VGG19
-
选择策略:
使用
torchvision.models.vgg16()。重要修改点:VGG 原生模型是输出 1000 类(ImageNet),需要把最后一层全连接层 (classifier) 修改为输出 11 类 -
交付物:在代码中运行
print(model)或使用torchsummary打印网络结构和参数量
任务 (8): VGG 预测输出 (3分)
- 核心要求:用训练好的 VGG 模型再次对测试集进行预测
- 交付物:生成
ans_vgg.csv文件 - 预期结果:VGG 的效果理论上应该比自己随便写的简单模型要好
(1) 请根据已有数据集,对training和validation进行处理,构造训练数据集
1.1. 数据检查
观察数据集名字,发现名字统一命名为 “数字_数字”。根据数据集介绍,前一个数字为类别编号,下划线后的数字为图片在类别里的编号。即 [类别]_[编号]
上网查找类别编号对应的标签,得到编号从0到10分别对应于:
# 11个食物类别
CLASS_NAMES = [
"Bread", "Dairy product", "Dessert", "Egg", "Fried food",
"Meat", "Noodles/Pasta", "Rice", "Seafood", "Soup",
"Vegetable/Fruit"
]了解了数据集基本结构后,开始构建数据集。
由图片命名格式可知,需要将图片名字的字符串使用 .spilt 进行切分,然后将对应的类别名字映射为图片名字前面的数字(类别编号)。
1.2. 定义数据集类
class FoodDataset(Dataset):
"""
Food-11 数据集的自定义 Dataset 类
文件名格式: [类别]_[编号].jpg
例如: 0_123.jpg 表示类别0(Bread)的第123张图片
"""初始化时获取所有图片,并且解析需要的类别标签(训练集和验证集的标签)。
def __init__(self, root, transform=None, mode='train'):
# 获取所有图片文件
self.images = sorted([f for f in os.listdir(root) if f.endswith('.jpg')])
# 如果不是测试集,解析标签
if mode != 'test':
self.labels = []
for img_name in self.images:
# 文件名格式: [类别]_[编号].jpg
label = int(img_name.split('_')[0])
self.labels.append(label)使用内置的.__getitem__方法,处理具体的每一张图片:
- 将图片转换为RGB数组
- 对图片应用
transform变换 - 然后根据是否是测试集,返回图片的文件名或者图片的标签名
def __getitem__(self, idx):
# 读取图片
img_path = os.path.join(self.root, self.images[idx])
image = Image.open(img_path).convert('RGB')
# 应用变换
if self.transform:
image = self.transform(image)
# 返回数据
if self.mode == 'test':
return image, self.images[idx] # 测试集返回图片和文件名
else:
return image, self.labels[idx] # 训练/验证集返回图片和标签再定义一个外置方法,返回图片的类别名字:
def get_class_name(self, label):
"""根据标签获取类别名称"""
return CLASS_NAMES[label]1.3. 创建数据集进行测试
创建数据集测试效果:
data_dir = 'datasets/food11'
simple_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
# 创建训练数据集
train_dataset = FoodDataset(
root=os.path.join(data_dir, 'training'),
transform=simple_transform,
mode='train'
)测试结果:
训练集样本数: 9866
类别数: 11
第一个样本:
图片形状: torch.Size([3, 224, 224])
标签: 0 (Bread)
各类别样本数:
0 (Bread): 994
1 (Dairy product): 429
2 (Dessert): 1500
3 (Egg): 986
4 (Fried food): 848
5 (Meat): 1325
6 (Noodles/Pasta): 440
7 (Rice): 280
8 (Seafood): 855
9 (Soup): 1500
10 (Vegetable/Fruit): 7091.4. 创建数据加载器方法
创建数据加载器方法,便于后续加载数据集进行模型训练。
def get_dataloader(data_dir, batch_size=64, train_transform=None, test_transform=None):
"""
创建训练集、验证集和测试集的 DataLoader
Args:
data_dir: 数据集根目录 (如 datasets/food11)
batch_size: 批次大小
train_transform: 训练集变换
test_transform: 验证集/测试集变换
Returns:
train_loader, val_loader, test_loader
"""(2) 为了保证数据的训练性能,请利用torchvision.transforms设计属于你的train_transform,train_transform模版已事先给出。你所设计的train_transform需要指定你所选择的特征图大小,并至少由五种transform组成
该部分代码位于
transforms.py中
由于每一张图片的大小并不统一,并且后续要使用 VGG16 模型进行训练,因此使用transforms.resize()方法,将图片大小统一为(224,224)。
查看transforms库的 API 接口,可以使用以下的方法扩展数据集,提高模型的性能。
.Resize:令所有图片尺寸统一为 VGG 模型需要的(224,224)。.RandomHorizontalFlip:以一个概率 进行随机的水平翻转。.RandomRotation:随机旋转一个特定的角度,此处选择degree=15.ColorJitter:随机改变图像的亮度、对比度、饱和度和色调。此处依次选择0.2,0.2,0.2,0.1。RandomAffine:随机进行仿射变换
注意:后续可视化展示时,如果 transform 里包含了
Normalize,图片颜色会变得很奇怪(因为数值被标准化)。在可视化时,可进行”是否选择Normalize”的对比。
因此定义两个数据集:实际使用的训练集train_transform和可视化展示的数据集visual_transform。此外顺便将验证集和测试集也变换为合适的尺寸大小,方便后续进行模型验证。
# 训练集变换
train_transform = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(15),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1), scale=(0.9, 1.1)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
visual_transform = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(15),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1), scale=(0.9, 1.1)),
transforms.ToTensor()
])变换结构显示:
Train Transform 包含以下变换:
1. Resize
2. RandomHorizontalFlip
3. RandomRotation
4. ColorJitter
5. RandomAffine
6. ToTensor
7. Normalize
共 7 种变换(3) 对你所设计的train_transform进行可视化,将变换后的结果进行可视化展示
方法设计
1. 设计一个反归一化函数,将 Normalize 后的图片还原用于显示
2. 设计一 visualize_transforms 函数,展示 transform 的效果
关键代码
-
denormalize()def denormalize(tensor): """反归一化,将 Normalize 后的图片还原用于显示""" mean = [0.485, 0.456, 0.406] std = [0.229, 0.224, 0.225] for t, m, s in zip(tensor, mean, std): t.mul_(s).add_(m) return tensor均值和方差使用著名的 ImageNet 数据集的统计值。后续对预训练的 VGG 模型进行二次训练时需要使用此数据,确保数据预处理的统一性。
-
visualize_transforms()def visualize_transforms(image_path, num_samples=5): """ 可视化 transform 效果 展示原图和多次增强后的结果 """ origin_img = Image.open(image_path).convert('RGB') fig, axes = plt.subplots(2, num_samples + 1, figsize=(15, 6)) # 第一行:原图 + 不带Normalize的增强效果 axes[0, 0].imshow(origin_img) for i in range(num_samples): transformed = visual_transform(origin_img) # ToTensor 后需要转换维度 [C, H, W] -> [H, W, C] img_np = transformed.permute(1, 2, 0).numpy() axes[0, i + 1].imshow(img_np) # 第二行:带 Normalize 的效果,不进行反归一化 resize_only = transforms.Compose([ transforms.Resize((IMG_SIZE, IMG_SIZE)), transforms.ToTensor() ]) axes[1, 0].imshow(resize_only(origin_img).permute(1, 2, 0).numpy()) for i in range(num_samples): transformed = train_transform(origin_img).clone() img_np = transformed.permute(1, 2, 0).numpy()
效果展示
增强效果=[Resize,随机水平翻转,随机旋转(15°),颜色抖动,随机仿射变换]1. 未进行反归一化:

第二行是经过设计的 transform 后未进行反归一化的图片。可以看到,相对于上方 transform 最后一层没加 Normalize 的图片,第二行包含 Normalize 变换后的图片,颜色变得很奇怪。图像呈现出奇怪的偏色:偏品红、偏绿,图片严重失真。
2. 进行反归一化:

第二行是经过设计的 transform 后并进行反归一化的图片。可以看到,相比于上一幅图的第二行,这幅图的第二行显得十分正常。原因就是经过了反归一化函数denormalize:
for i in range(num_samples):
transformed = train_transform(origin_img).clone()
# 反归一化
img_denorm = denormalize(transformed)
img_denorm = img_denorm.clamp(0, 1) # 限制在 [0, 1]
img_np = img_denorm.permute(1, 2, 0).numpy()(4) 搭建好个人设计的训练模型,并利用tensorboard对过程进行可视化展示
CNN网络结构
模型展示(位于model.py):
class FoodCNN(nn.Module):
"""
自定义 CNN 模型用于 Food-11 分类
结构: 4层卷积 + 3层全连接
"""FoodCNN(
(features): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(8): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): ReLU(inplace=True)
(11): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(12): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(14): ReLU(inplace=True)
(15): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=50176, out_features=512, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=512, out_features=128, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=128, out_features=11, bias=True)
)
)
输入形状: torch.Size([2, 3, 224, 224])
输出形状: torch.Size([2, 11])
总参数量: 26,147,083
可训练参数量: 26,147,083训练流程
-
导入预先定义的变换和数据加载器
from dataloader import get_dataloader, CLASS_NAMES from transforms import train_transform, test_transform from model import FoodCNN -
定义每一个 epoch 的训练循环
def train_one_epoch(model, train_loader, loss_fn, optimizer, device): """ 一个 epoch 的训练 :return: epoch_loss: 该批次的平均损失 epoch_acc: 该批次的平均准确率 """具体循环:
for images, labels in tqdm(train_loader, desc='Training', leave=False): images, labels = images.to(device), labels.to(device) optimizer.zero_grad() outputs = model(images) loss = loss_fn(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() _, predicted = outputs.max(1) total += labels.size(0) correct += predicted.eq(labels).sum().item() -
定义验证函数
def validate(model, val_loader, criterion, device): """验证模型""" """ epoch_loss: 该批次的平均损失 epoch_acc: 该批次的平均准确率 """ with torch.no_grad(): ... -
定义完整的训练流程
def train(config): """完整训练流程"""- 选择训练设备
- 加载训练集、验证集
- 实例化模型
- 使用 Tensorboard 记录模型结构
- 进入训练循环
- 进入训练集循环
- 进入验证集循环
- 学习率调度
- Tensorboard 记录训练损失值、准确率、学习率
- 保存最优模型
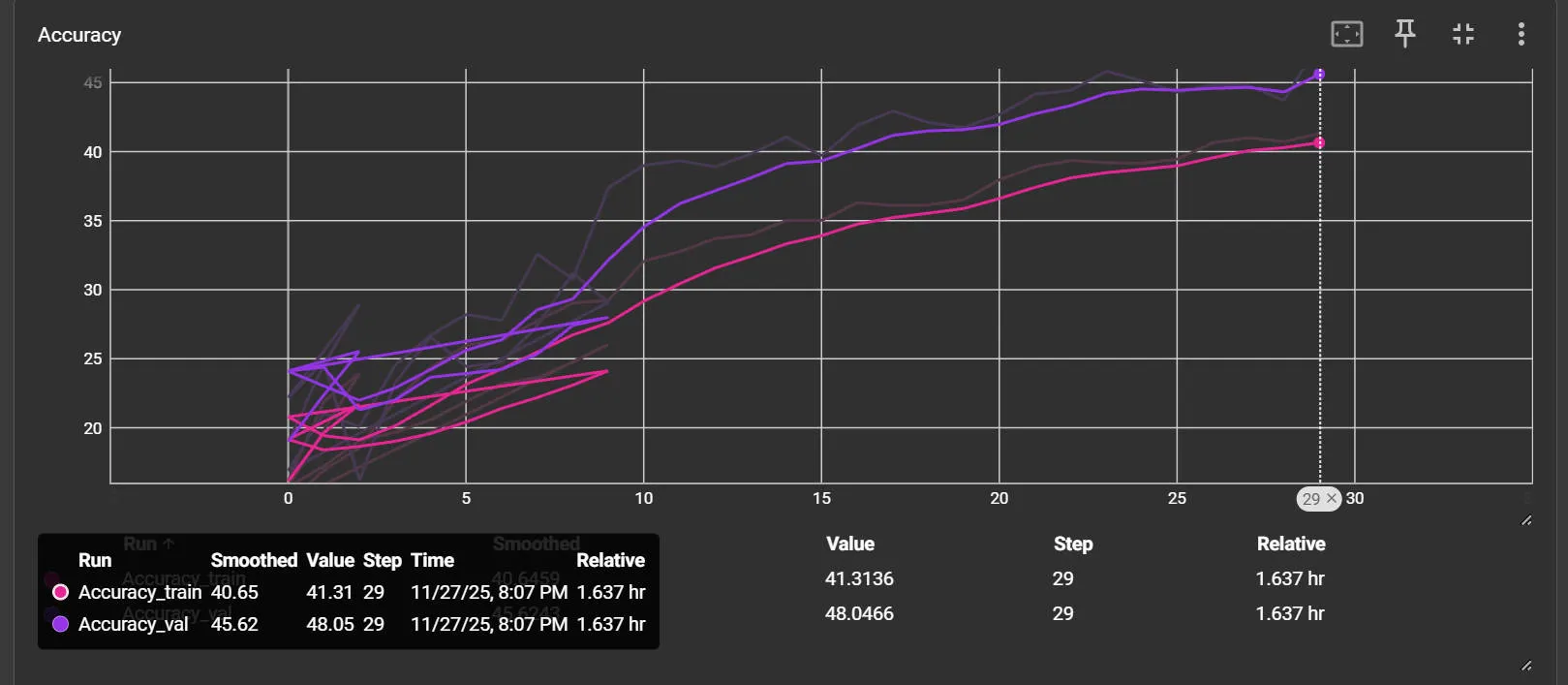
结果展示
准确率
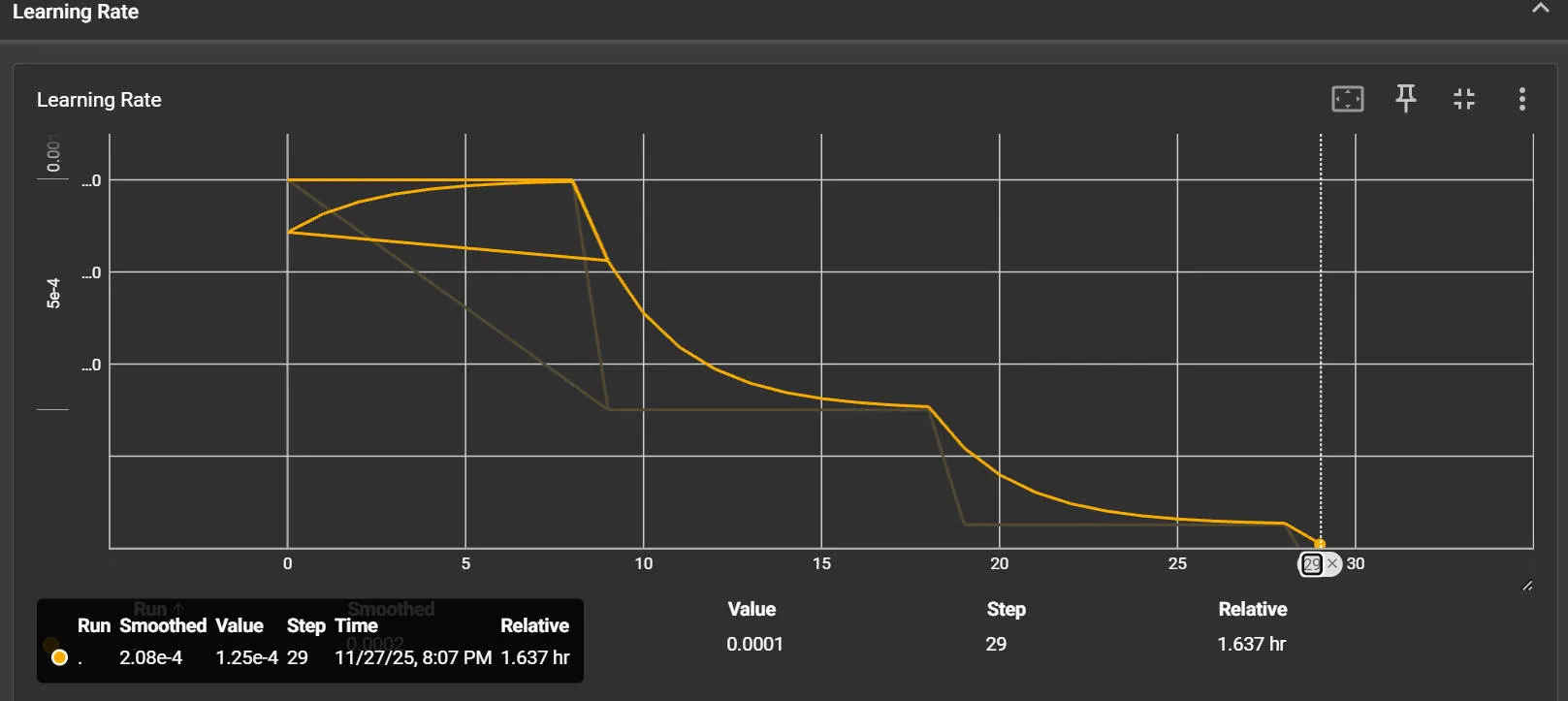
学习率
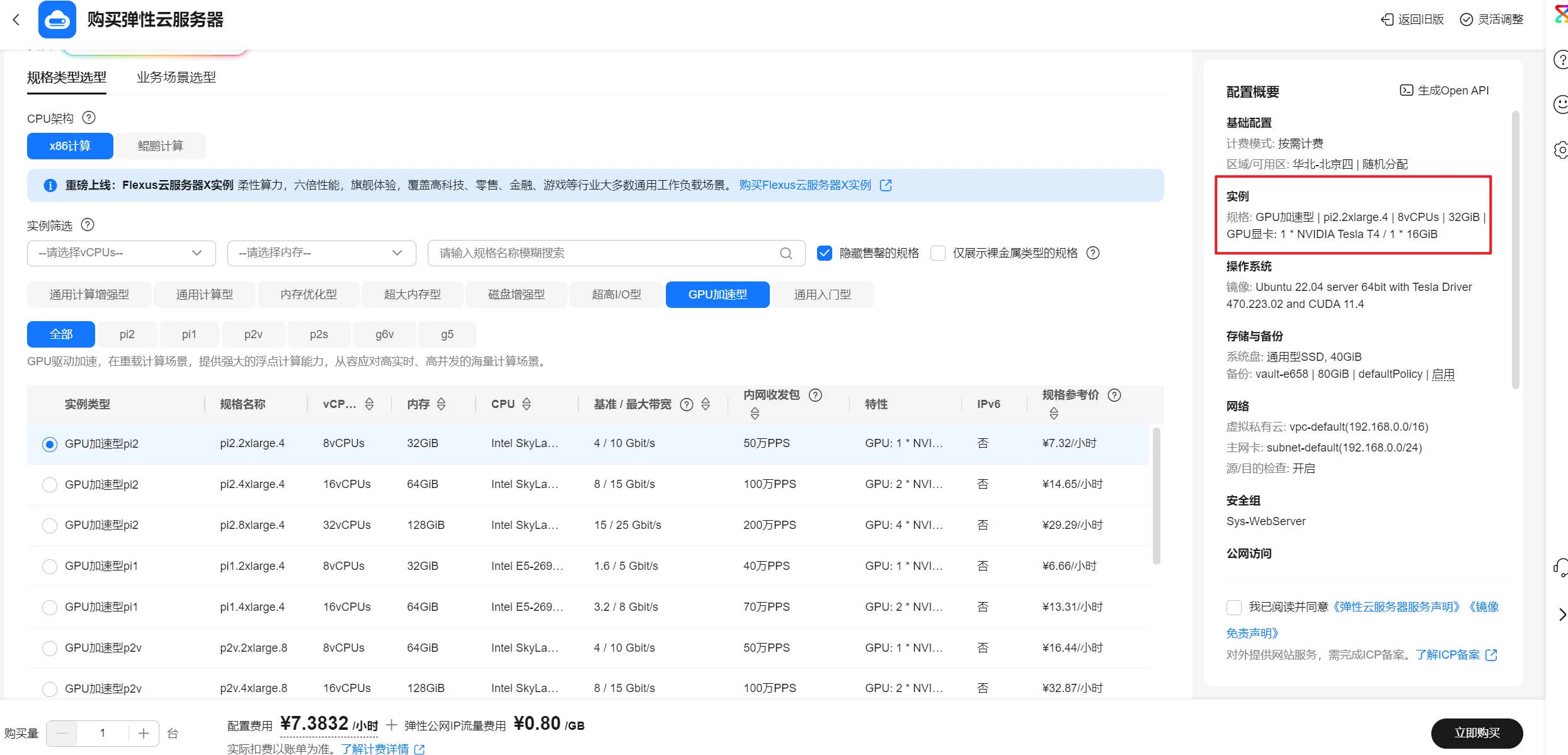
由于本地4060显卡跑得太慢,故转移到华为云使用 T4 卡进行训练。
印象里就算使用 T4 也跑了 30 分钟以上,跑模型还是太烧钱了。
(5) 在验证集上显示你的准确性和混淆矩阵
def evaluate(model, val_loader, device):
"""评估模型,返回预测结果和真实标签"""
def plot_confusion_matrix(y_true, y_pred, class_names, save_path='confusion_matrix.png'):
"""绘制混淆矩阵"""输出结果:
验证集准确率: 47.93%
分类报告:
precision recall f1-score support
Bread 0.31 0.45 0.37 362
Dairy product 0.80 0.03 0.05 144
Dessert 0.35 0.44 0.39 500
Egg 0.37 0.31 0.34 327
Fried food 0.46 0.29 0.35 326
Meat 0.56 0.69 0.62 449
Noodles/Pasta 0.45 0.30 0.36 147
Rice 0.72 0.14 0.23 96
Seafood 0.58 0.33 0.42 347
Soup 0.63 0.83 0.72 500
Vegetable/Fruit 0.61 0.71 0.65 232
accuracy 0.48 3430
macro avg 0.53 0.41 0.41 3430
weighted avg 0.50 0.48 0.46 3430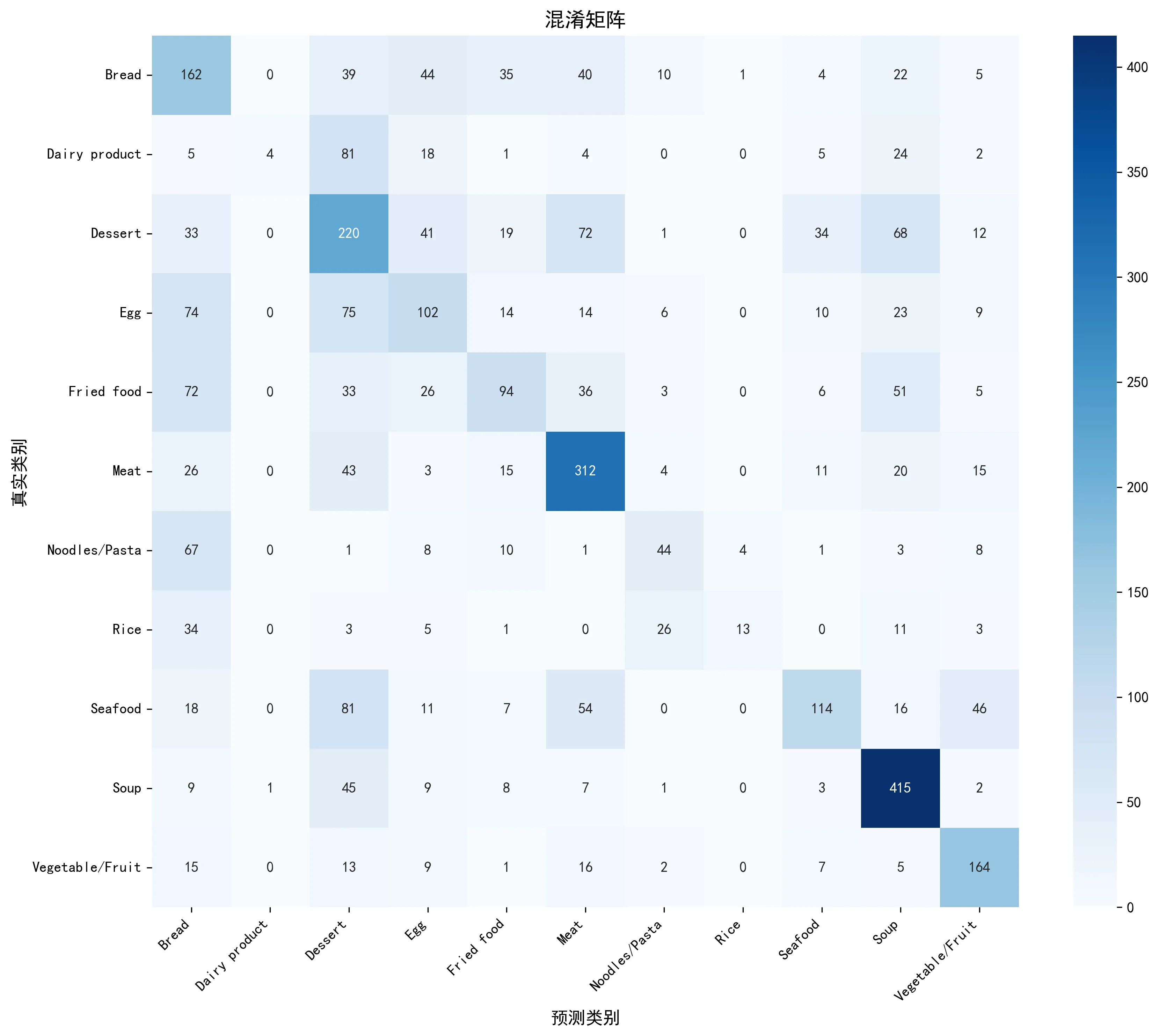
可以看到,该自定义CNN模型表现出明显的偏科。它能准确识别汤(Soup)、肉(Meat)等特征鲜明的食物,但对奶制品(Dairy product)、鸡蛋(Egg)和米饭(Rice)等类别则出现严重混淆,特别是将大量奶制品误判为甜点。这表明该模型结构虽合理,但对于学习视觉上相似或概念重叠的细粒度特征能力不足。
(6) 将个人设计模型对测试集预测结果输出到ans_ours.csv中
def main():
output_path = 'ans_ours.csv'
model = FoodCNN(num_classes=11).to(device)
model.load_state_dict(torch.load(model_path))
print(f"已加载模型: {model_path}")
model = model.to(device)
# 预测结果
filenames, predictions = predict(model, test_loader, device)
df = pd.DataFrame({
'Id': filenames,
'Category': predictions
})
df.to_csv(output_path, index=False)预测结果已保存到: ans_ours.csv
共 3347 条预测
前10条预测结果:
Id Category
0 0_0.jpg 0
1 0_1.jpg 3
2 0_10.jpg 0
3 0_100.jpg 5
4 0_101.jpg 2
5 0_102.jpg 0
6 0_103.jpg 2
7 0_104.jpg 0
8 0_105.jpg 0
9 0_106.jpg 3“ans_ours.csv”会放到附件中上传。
(7) 请自行查询资料,搭建VGG系列模型,并打印模型参数
查资料得:
VGG网络是计算机视觉领域的经典卷积神经网络架构。其核心特点是结构规整,全网统一使用 的小卷积核和 的最大池化层,通过重复堆叠卷积层块(Block)来增加网络深度,从而提取更高级的语义特征。
- VGG16:由5个卷积块组成,包含 13个卷积层 和 3个全连接层(共16层权重层)。从日志可见,其总参数量约为 1.34亿
- VGG19:在VGG16的基础上增加了卷积深度,包含 16个卷积层 和 3个全连接层(共19层权重层),参数量增至约 1.4亿
为适配 Food-11 数据集,将两个模型的最终全连接层均修改为 11维输出。由统计信息可知,VGG系列模型的参数主要集中在第一个全连接层(约1亿参数),导致模型体积较大(>500MB),对计算资源有较高要求。
VGG16 模型结构
VGG16Food(
(vgg): VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=11, bias=True)
)
)
)
VGG16 参数统计
总参数量: 134,305,611
可训练参数量: 134,305,611
参数大小: 512.34 MB
输入形状: torch.Size([2, 3, 224, 224])
输出形状: torch.Size([2, 11])
===================================================================================================================
===================================================================================================================
VGG19 模型结构
VGG19Food(
(vgg): VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): ReLU(inplace=True)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): ReLU(inplace=True)
(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): ReLU(inplace=True)
(32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(33): ReLU(inplace=True)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): ReLU(inplace=True)
(36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=11, bias=True)
)
)
)
VGG19 参数统计
总参数量: 139,615,307
可训练参数量: 139,615,307
参数大小: 532.59 MB(8) 使用VGG系列模型对测试集进行预测,并将结果输出到ans_vgg.csv中
模型二次训练
训练代码和训练自定义 CNN 模型时一模一样,只给出区别代码,不过多重复。
def train(config):
# VGG16 模型 (使用预训练权重)
model = VGG16Food(num_classes=11, pretrained=True).to(device)
print("已加载 VGG16 预训练权重")
if __name__ == '__main__':
config = {
'data_dir': 'datasets/food11',
'batch_size': 64,
'epochs': 15, # 二次训练轮数可以低一点(显卡照样顶不住)
'lr': 0.0001,
'log_dir': 'runs/vgg16',
'save_path': 'best_vgg16.pth'
}模型预测
代码和预测自定义 CNN 模型时一样。
data_dir = 'datasets/food11'
model_path = 'best_vgg16.pth'
output_path = 'ans_vgg.csv'预测结果输出到 “ans_vgg.csv”中。
预测结果:
验证集准确率: 90.96%
分类报告:
precision recall f1-score support
Bread 0.88 0.86 0.87 362
Dairy product 0.95 0.80 0.87 144
Dessert 0.85 0.91 0.88 500
Egg 0.87 0.89 0.88 327
Fried food 0.93 0.90 0.91 326
Meat 0.91 0.91 0.91 449
Noodles/Pasta 0.95 0.98 0.97 147
Rice 0.96 1.00 0.98 96
Seafood 0.91 0.89 0.90 347
Soup 0.96 0.96 0.96 500
Vegetable/Fruit 0.96 0.94 0.95 232
accuracy 0.91 3430
macro avg 0.92 0.91 0.92 3430
weighted avg 0.91 0.91 0.91 3430
===================================================================================================================
预测结果已保存到: ans_vgg.csv
共 3347 条预测
前10条预测结果:
Id Category
0 0_0.jpg 0
1 0_1.jpg 0
2 0_10.jpg 0
3 0_100.jpg 0
4 0_101.jpg 0
5 0_102.jpg 0
6 0_103.jpg 2
7 0_104.jpg 0
8 0_105.jpg 0
9 0_106.jpg 0